We’ve been dabbling with creating iOS apps for awhile now. Text Stats is just one little experiment. We thought it would be interesting for us to talk the process and evolution.
Firstly, we are big proponents of the Web. When something can be done in HTML, it should. What we are interested in, when developing native applications, are all the places that the Web is not (yet) available. For instance, with Text Stats we focused on being an “Action Sheet” recipient app. That means from any application (or webpage) the text can be send into an application, of which Text Stats is one.
The new Shortcuts.app is the other place we explored for Text Stats. This is an automator style application on iOS which allows you to build larger workflows. Now Text Stats exposes several small functions to return word count and other metrics from text supplied to the function. We’re not exactly sure what it’s good for, but that’s part of the Unix philosophy. To build small, focused applications that can be building blocks of something larger.
If this sounds interesting, download the app to give it a try.
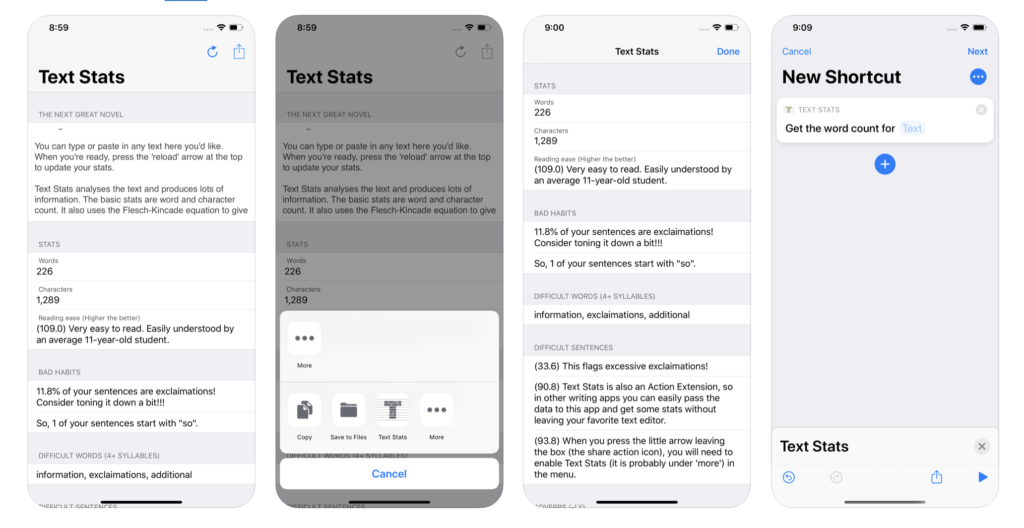
On iOS and Android, there is a concept of an action extension. In iOS when you press the share button and another modal dialog appears allowing you to select a different application to receive the sent data. These interactions allow you todo simple things like email a link to an article, post images and text to social media or export data to the file system. For your app to be in this list you need to be a registered first-class application.
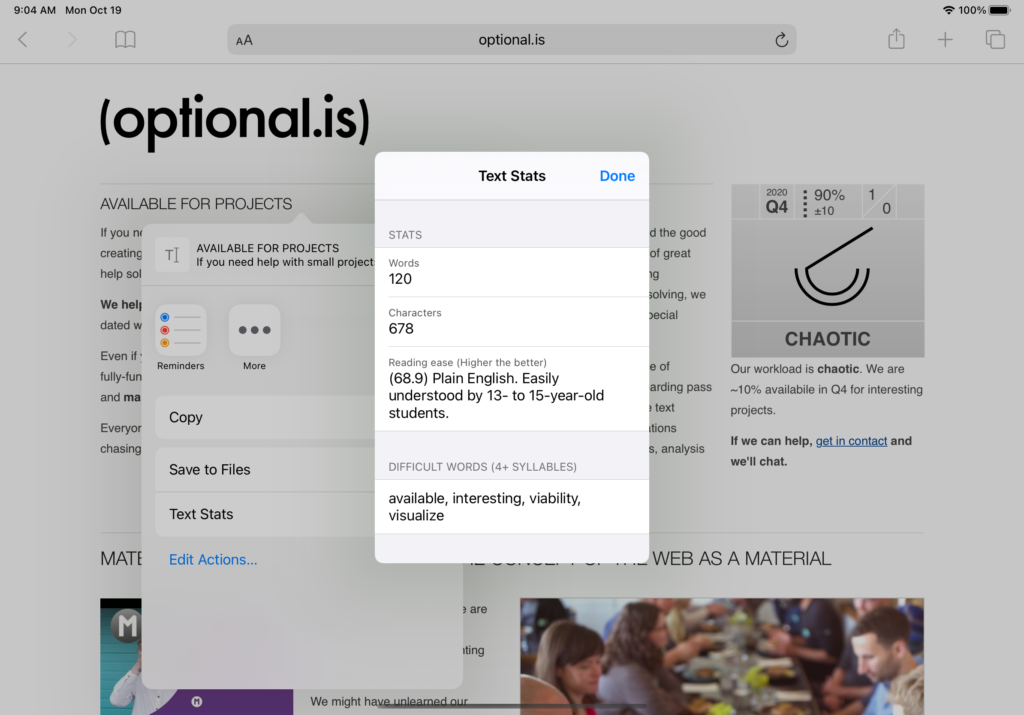
The W3C has a “Web Share API” but that is to accept text, media or links and open the native sharing, action dialog and pass that information to local applications or remote sources. What Text Stats app does, is receive that data. For now, this isn’t a replacement for a local application.
Those nooks and crannies where the Web hasn’t arrived yet is where we want to explore. The apps we build are helpful little utilities that scratch our own itch and learn more. We only release them because, someone else might find them useful too.
Keeping an eye on trends, we see more and more people are (or are trying) to use tablets as their daily computer. There are a lot of writing and note taking apps appearing to fill the gap where enterprise hasn’t yet taken over. Many aren’t geared for actually writing better, they have better, cleaner, simpler design, syncing or other features.
What we want is a tool to improve our writing. This includes; word count, adverb warnings, etc. Rather than try to compete as yet another word processor app, we decided to build an action extension. That way, in any writing app you can access Text Stats.
Text Stats benefits from several years of experience with Natural Language Processing and dealing with text. What we aimed for was something similar to the old “writer’s workbench” tool. WWB flagged sentences that would be hard to read, use of passive voice, warned about adverbs and more.
Hemingway.app is a great start, but it is a dedicated app. We wanted something slightly agnostic as an action extension.
The first thing we did was to create a new TextStats class which contains all the functions. This makes the code more portable across apps. For those of you without iOS development knowledge, you need to always create a base iOS app. Then, inside that app you can embed additional apps such as the Today widget, Action extensions, Watch apps, etc. To avoid duplicating code across all these embedded app options we created the TextStats class and shared it between the different app extensions.
We started with the easy stuff like getting a character count of a string. We then tried to get a rough word count by exploding on the space character. These are both a quick and good estimation of how long blob of text is. If you miss a few items it averages itself out in the end.
Are contractions one or two words? (Can’t, won’t, don’t, etc.) If we then split on apostrophes to make those into two words, we risk separating others like O’Reilly. Sometimes it makes senses, sometimes it doesn’t.
Then we get to hyphenated words. Today used to be written To-day. Rock-n-roll or Rock’n’roll? Red-handed versus redhanded. If you split on hyphens it sometimes makes sense as multiple words, sometimes it doesn’t
What about URLs? https://example.com/foobar/at/my/homework/ How many “words” is that string?
Next, after splitting on spaces, we loop through the array of words and try to estimate syllables for each. In English this isn’t easy due to all the loan words we have incorporated into the language. As a rough first pass, every sequence of vowels counts as a new syllable. “Seek” only has one set of sequential vowels so it only has one syllable. Other words like “only” has an o and a y separated by consonants so this has two syllables. It doesn’t work for all words, but as a quick estimate it works fine.
There was one last thing we needed and that was a sentence count. That sounds simple, but actually it requires some gymnastics. Normally we just explode on full-stops. But then we aren’t getting question or exclamation sentences. To fix this we did a find and replace on ?! and converted them to . Now we could explode on full-stops and get a sentence count.
Using word count per sentence and syllables per word, it is possible to estimate some “reading ease“. This is a number to better estimate the overall text difficulty. The idea behind this equation was to help writers write to a level which most of their audience would understand.
There is an oft cited “fact” that newspapers are written at a sixth grade reading level, as if this were a comment on the dumbing down of society. It isn’t. Things that are easier to read are more accessible to a wider audience. It doesn’t mean they aren’t tackling difficult or nuanced topics, just that it is written in an easily understandable way!
The first version of Text Stats incorporated just these features:
- Word count
- Character count
- Reading ease
- Exclamation count
- Difficult words (3 or more syllables)
- Difficult sentences
- Adverbs (words ending in -ly)
We created a simple iOS app to accept text input and echo back the results along with an action extension which received text from the parent app and showed a table of these stats in return.
Fixes
As we began to paste in text from other sources we quickly found problems. Using new lines \n instead of a full stop (for instance in lists or “read more” link). Our naïve word parse also was getting other punctuation as parts of words like quotes and commas.
As adults with advanced educations some of the words in the “difficult word list”, like “television” puzzled us. It is there because it has 3 or more syllables. We raised the bar to 4 or more syllables. Similarly with “difficult sentences” some rated very high in difficulty but only has two words in it. We need to add a minimum word count to a sentence for it to be considered for ranking.
To fix many of these problems we “cleaned” the text with find and replaces for quotes, commas and other punctuation. The downside was as we computed the statistics we were echoing back these altered strings. Which means that it might be hard to find in the source text. Keeping a shadow “original” text is necessary.
To fix these issues we went back and were not so naïve as we split on spaces, but revamped the parser to be more like a SAX parser and consume one character at a time and decide if we are in a word or not.
GUI
Let’s talk about UISplitViewController. You have probably seen this if you have used the mail app. On smaller screens like iPhones you get to see the “main view” which is usually a list of emails. When you click a cell, it moves to the detail view of the actual message. On larger screens like the iPad you see the main view as a left column and the detail view as the majority of the screen.
Moving the existing code into the split view controller was pretty easy, but what came next wasn’t. When you think something is simple, it usually is for 80% of the use-cases, but if you want to design something well, then you need to keep exploring. For instance, the phone has two orientations. On the non-plus size phones, the landscape and portrait views show you only the main view list. But on the plus size phones you get main and detail when in landscape. The iPad is even more convoluted because you have landscape and portrait, but also split screen. In portrait it is 50/50 and in landscape it is 66/33, 50/50, & 33/66. This means you are not always getting both views on the screen.
Normally, that’s not a big deal, but we are cheating. When you ONLY see the main view we sneak in an additional section and table cell with a textarea for text input. But on a larger screen we hide the text input in the main view and use the detail view as the writing canvas.
If this were CSS it would be easy to display this based on media queries, but this isn’t CSS. We need to check all sorts of things. The isCollapsed flag, check when the device rotated and is redrawn to check the new status. In browsers the event to redraw the CSS is run with every tiny change. On iOS you need to add those hooks yourself where you feel it is important.
Things like this sucked a bunch of time so development on features stalled.
We also reached out to a few more people to beta test the app. We got a bunch of great feedback and smashed a few more bugs here and there.
We also got some feedback about what additional text stats people would be interested in. We only managed to get one personal pet-peeve included. We created a new section called “bad habits” and added a check for sentences starting with “So”. This section will continue to grow with other pet-peeves which hopefully will be useful for others.
In the end, we also swapped out our home-built word parser for the built-in NLP parser. There are a few discrepancies. Firstly, the built in NLP would split contractions. That accounted for a slight difference in word count. Our code would handle URLs as a special case. Whereas the NLP parser did not and the // in https:// acted as a word boundary.
The NLP parser gives us better sentence splitting but also POC (part of speech) for each of the words. This allows us to correctly identify things like adverbs ending in -ly, compared to just words ending in -ly.
It can also help us to identify pronouns. This is very useful for other types of text analysis we want to include in the future. (We won’t go into this now, but there is a lot of research around pronoun usage to signal pecking order, gender guessing, etc. from text. There is a lot of inherent bias, cultural issues and snake oil. So none of this is in the app.)
We add some code to count over used words like “simply”. Most of the time, you can remove this word without changing any meaning and at the same time not making the reader feel bad when it isn’t “simple” for them.
Siri
The horribly named Siri Shortcuts, which expose some of your app’s functionality in the Shortcuts app, but also Siri (sort of), was our next step in exploring places the Web isn’t (directly yet) welcome.
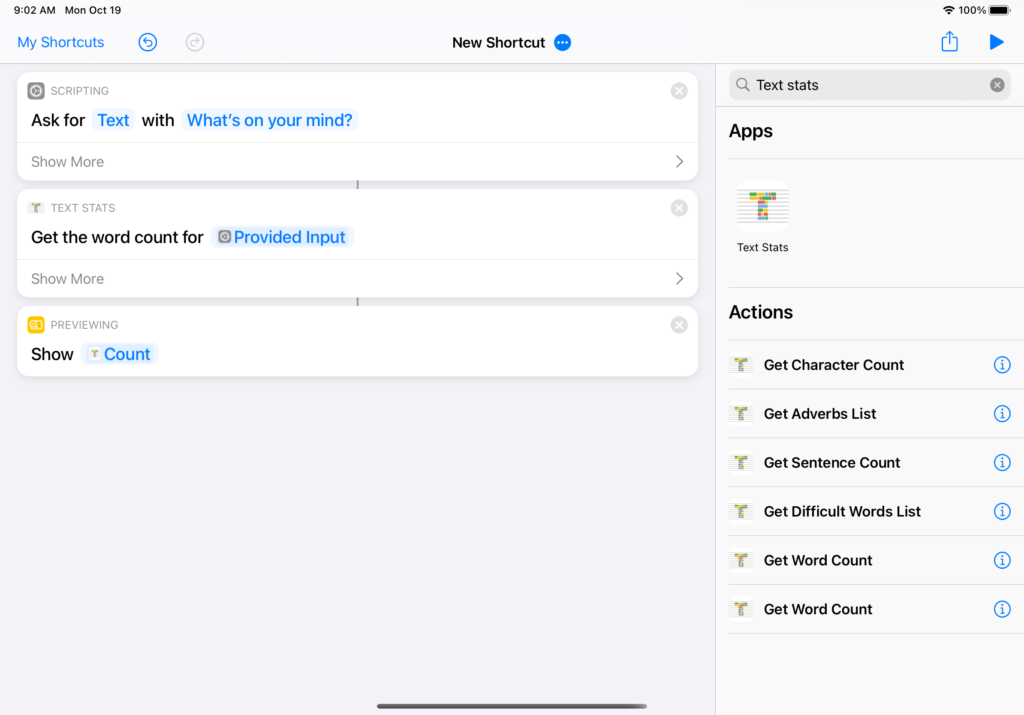
As you build-up complex workflows, you can use Text Stats to extract some metadata, like word count, sentence count, etc. What you use these for in your workflow is up to you.
We don’t have a practical use for this, yet, but we learnt a lot about how Shortcuts work for any future projects. And who know, maybe someone out there needs this exactly tool for their writing workflow? Now’s it’s possible to chain Text Stats together into something larger.
NaNoWritMo
National Novel Writing Month (NaNoWritMo) is in November. We’ll try to support anyone interesting in try to write better by making the app free during this time.
If you find Text Stats interesting or useful, let us know.